- 官网介绍
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
前言
数据在传递过程中需具备高吞吐、高容错等特性,显然这些对于kafka来说都具备,相对flume来说,kafka的组成部分较多,因此首先需要清楚的知道各个部分都有什么含义,那么本篇仍旧按照是什么,怎么用,核心问题有哪些结构展开。
一、是什么
kafka是一个分布式消息队列。
传统的消息传递方法包括两种,kafka消息传递方式属于后者,这就好比你使用微信群发消息,或者给张三发送消息。那么有可能张三并没有登微信,那么李四发给张三的消息并没有因此消失,张三再次登陆上去时仍会接到这条消息,那么这就是kafka使用的场景(我并不知道微信使用的什么技术来收发消息,此处只是给出一个实例而已)。
排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。
发布-订阅:在这个模型中,消息被广播给所有的用户。
首先,从数据组织形式来说,kafka有三层形式,kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
当收到的消息时先buffer起来,等到了一定的阀值再写入磁盘文件,减少磁盘IO.在一定程度上依赖OS的文件系统(对文件系统本身优化⼏乎不可能)
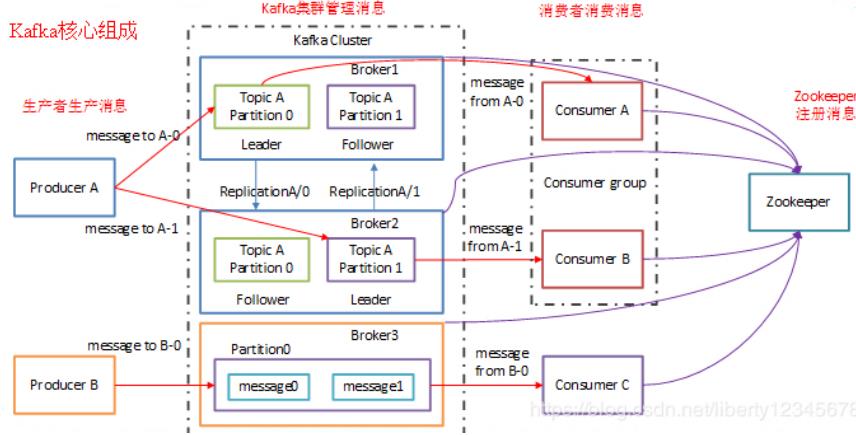
- 关于上图文字介绍如下
首先消息的发出者有producerA和producerB
producerA发送了两条消息,这两条消息同属一个topic,这同一个topic又有两个分区partion0和partition1,这两个分别位于broker1和broker2上,于此同时这两条消息message a-0、message a-1各有一个副本,而每条消息与副本通过zookeeper选举出一个leader,此时这个comsumer group类似一个群的作用接收topic下的所有消息,comsumer group下的comsumerA消费作为leader的消息message a-0、comsumerB消费作为leader的消息message a-1,至此producerA产生的消息都被消费了。
producerB发送出了一条消息,此时只有一个分区,位于broker3上,当然此时副本有且只能有一个,这条消息被唯一的消费者comsumerC消费,至此producerB产生的消息都被消费了。
本图是官方给出的,红色字体是后面加上去的,那么理解这个图是很有必要的,首先这个图涉及的全面,一个分区一个消费者是怎么消费数据的,多个分区时是它的副本策略是什么样的,消费者组具体是怎么消费数据的,zookeeper这个组件在其中起到了很大的作用。
- producer
消息生产者,向kafka broker发消息的客户端
- broker
Kafka集群每个节点启动的角色(java进程),这里就涉及到一个问题:假设有3个broker,也就是3台机器,如果刚好有三个分区,一台机器上各占一个分区这是最合适的情况,那么实际生产中机器数量有限,一般会出现分区数大于机器数的情况,那么就是每台机器上要传输多个分区上的数据,那么此时就尽可能让每台机器上的分区一样多。
- topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,用来划分生产者和消费者处理的消息类型,消息分类按不同类别,分成不同的Topic,Topic⼜拆分成多个partition,每个partition均衡分散到不同的服务器(提⾼并发访问的能⼒)。
在JMS实现中,Topic模型基于push⽅式,即broker将消息推送给consumer端.不过在kafka中,采⽤了pull⽅式,即consumer在和broker建⽴连接之后,主动去pull(或者说fetch)消息;这种模式有些优点,⾸先consumer端可以根据⾃⼰的消费能⼒适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch.
- partition
每个主题可以设置若干个分区,将数据分散在集群的各个几点,解决数据倾斜,提高处理的并发度
一个partition中的消息只会被group中的⼀个consumer消费;每个group中consumer消息消费互相独⽴;我们可以认为⼀个group是⼀个”订阅”者,⼀个Topic中的每个partions,只会被⼀个”订阅者”中的⼀个consumer消费,不过⼀个consumer可以消费多个partitions中的消息。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。因为业务不同分区数具体多少根据需求来定。网上查找资料大致认为分区数设置为机器数的2-3倍比较合适。
消费者按顺序从partition中读取,不⽀持随机读取数据,但可通过改变保存到zookeeper中的offset位置实现从任意位置开始读取
分区写入策略:kafka如何将数据分配到不同分区中的策略.常见的有三种策略,轮询策略,随机策略,和按键保存策略。其中轮询策略是默认的分区策略,而随机策略则是较老版本的分区策略,不过由于其分配的均衡性不如轮询策略,故而后来改成了轮询策略为默认策略。
- replication
副本,为了提高数据的安全性,每个分区可以设置多个副本保存在其他的broker上
- leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。为什么follower副本为什么不对外提供服务?为了保证消费消息时的一致性,不能消费者a拿到了数据,而消费者b还没有拿到数据(如果有follower涉及从leader处拿数据这一动作,那么就需要时间,那么就会存在从follower消费数据会慢于leader时的状况)。
- follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
- consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
- consumer group
消费者组,这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.如果所有的consumer都具有不同的group,那这就是”发布-订阅”;消息将会⼴播给所有的消费者.
- offset
偏移量,生产者写入kafka的每条数据都会带一个序号,这个编号就叫做偏移量。
- zookeeper
Zookeeper主要用于在集群中不同节点之间进行通信,在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取,除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等
二、怎么用
怎么用之前,先了解他是怎么装的
安装配置
- zookeeper配置
vim zoo.cfg
# 用来存储zk的数据
dataDir=/opt/zookeeper/data
# 配置集群信息
# server.id=主机名:通信端口:选举端口
server.1=bd0501:2888:3888
server.2=bd0502:2888:3888
server.3=bd0503:2888:3888
vim myid
在zoo.cfg中设置的dataDir下,创建一个名为myid的文件,myid文件中写上当前机器对应的id号
- 启动zookeeper
zkServer.sh start
- kafka配置
- vim server.properties
# 为每个borker设置一个集群内唯一的id号(每个机器不一样)
broker.id=1
# 为每个borker设置服务的主机名和端口(每个机器不一样)
listeners=PLAINTEXT://bd0501:9092
# kafka这里的log,指的是两类log文件
# 第一类:broker的运行日志
# 第二类:kafka用来存储message的文件,这个文件也叫store log
# 通常需要创建一个目录单独保存
log.dirs=/opt/kafka-2.4.1/logs
# zk集群地址
zookeeper.connect=bd0501:2181,bd0502:2181,bd0503:2181
- 配置环境变量
> 根据用户的不同环境变量的地址不同
echo 'export KAFAK_HOME=/opt/kafka-2.4.1' >> /etc/profile
echo 'export PATH=KAFAK_HOME/bin:PATH' >> /etc/profile
source /etc/profile
- 后台启动kafka
kafka-server-start.sh -daemon /opt/kafka_2.11/config/server.properties
- 吞吐量测试命令
- 测试生产者
命令
kafka-producer-perf-test.sh --topic king01 --num-records 1000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=cdh0053:9092,cdh0054:9092
结果
370756 records sent, 74136.4 records/sec (7.07 MB/sec), 342.5 ms avg latency, 1274.0 ms max latency.
218116 records sent, 40968.4 records/sec (3.91 MB/sec), 576.5 ms avg latency, 3829.0 ms max latency.
215033 records sent, 43006.6 records/sec (4.10 MB/sec), 6060.6 ms avg latency, 7247.0 ms max latency.
1000000 records sent, 60613.407686 records/sec (5.78 MB/sec), 2023.15 ms avg latency, 7247.00 ms max latency, 923 ms 50th, 6967 ms 95th, 7177 ms 99th, 7242 ms 99.9th.
- 测试消费者
命令
kafka-consumer-perf-test --broker-list cdh0053:9092,cdh0054:9092 --messages 50000000 --topic king01 --threads 1 --timeout 60000 --print-metrics --num-fetch-threads 6
结果
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
WARNING: Exiting before consuming the expected number of messages: timeout (60000 ms) exceeded. You can use the --timeout option to increase the timeout.
2020-11-09 17:38:30:705, 2020-11-09 17:39:38:189, 190.7349, 2.8264, 2000000, 29636.6546, 3072, 64412, 2.9612, 31050.1149
三、核心问题
经常要讨论的问题就是数据在传输过程中丢失了怎么解决,如果数据源头的生产数据速度大于消费数据的速度怎么解决,生产中重复、消费中重复也是常常面临的问题,怎么样使集群满足生产需求的同时性能处于最优是我们最终要关注的东西。
数据丢失问题的解决方式
- ISR
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas)。
同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度”是指可以忍受的滞后范围,这个范围可以通过参数进行配置。如果持续拉取速度慢于leader副本写入速度,慢于时间超过replica.lag.time.max.ms后,它就变成“非同步”副本,就会被踢出ISR副本集合中。但后面如何follower副本的速度慢慢提上来,那就又可能会重新加入ISR副本集合中了。
- 数据丢失:
acks=1的时候(只保证写入leader成功),如果刚好leader挂了。数据会丢失。
acks=0的时候,使用异步模式的时候,该模式下kafka无法保证消息,有可能会丢。
2. brocker如何保证不丢失:
acks=all : 所有副本都写入成功并确认。
retries = 一个合理值。
min.insync.replicas=2 消息至少要被写入到这么多副本才算成功。该属性规定了最小的ISR数。这意味着当acks为-1(即all)的时候,这个参数规定了必须写入的ISR集中的副本数,如果没达到,那么producer会产生异常。
unclean.leader.election.enable=false 关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失。
- Consumer如何保证不丢失
如果在消息处理完成前就提交了offset,那么就有可能造成数据的丢失。
enable.auto.commit=false 关闭自动提交offset
处理完数据之后手动提交。
Kafka 的消息投递保证(delivery guarantee)机制以及如何实现
Kafka支持三种消息投递语义:
At most once 消息可能会丢,但绝不会重复传递
At least one 消息绝不会丢,但可能会重复传递
Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户想要的
consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中存下该consumer在该partition下读取的消息的offset,该consumer下一次再读该partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
可以将consumer设置为autocommit,即consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。但实际上实际使用中consumer并非读取完数据就结束了,而是要进行进一步处理,而数据处理与commit的顺序在很大程度上决定了消息从broker和consumer的delivery guarantee semantic。
·读完消息先commit再处理消息。这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once。
读完消息先处理再commit消费状态(保存offset)。这种模式下,如果在处理完消息之后commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就对应于At least once。
数据积压问题
数据积压,从字面上来看意味着消费能力不足,或者产生速度过快,那么首先从数据是怎么消费的这一方面进行理解
kafka的消费者方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适,它可简化broker的设计,consumer可自主控制消费消息的速率,同时consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,我们在我们的拉请求中有参数,允许消费者请求在等待数据到达的“长轮询”中进行阻塞。
数据积压
(1)如果是Kafka消费能力不足,则可以考虑增加 topic 的 partition 的个数,同时提升消费者组的消费者数量,消费数 = 分区数 (二者缺一不可)
(2)若是下游数据处理不及时,则提高每批次拉取的数量。批次拉取数量过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。
kafka的balance是怎么做的
官方原文
Producers publish data to the topics of their choice.
The producer is able to choose which message to assign to which partition within the topic.
This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the message).
More on the use of partitioning in a second.
生产者将数据发布到他们选择的主题。生产者可以选择在主题中分配哪个分区的消息。这可以通过循环的方式来完成,只是为了平衡负载,或者可以根据一些语义分区功能(比如消息中的一些键)来完成。
在如下条件下,partition要在consumer中重新分配:
条件1:有新的consumer加入
条件2:旧的consumer挂了
条件3:coordinator挂了,集群选举出新的coordinator
条件4:topic的partition新加
条件5:consumer调用unsubscrible(),取消topic的订阅
均衡的最终目的,是提升topic的并发消费能力,常见的有三种情况会触发Rebalance:
组成员数发生变更
订阅主题数发生变更
订阅主题的分区数发生变更
kafka数据分区和消费者的关系,kafka的数据offset读取流程,kafka内部如何保证顺序,结合外部组件如何保证消费者的顺序?
- kafka数据分区和消费者的关系:
1个partition只能被同组的⼀个consumer消费,同组的consumer则起到均衡效果 - kafka的数据offset读取流程
1.连接ZK集群,从ZK中拿到对应topic的partition信息和partition
的Leader的相关信息
2.连接到对应Leader对应的broker
3.consumer将⾃⼰保存的offset发送给Leader
4.Leader根据offset等信息定位到segment(索引⽂件和⽇志⽂
件)
5.根据索引⽂件中的内容,定位到⽇志⽂件中该偏移量对应的开始
位置读取相应⻓度的数据并返回给consumer -
kafka内部如何保证顺序:
kafka只能保证partition内是有序的,但是partition间的有序是没办法的。爱奇艺的搜索架构,是从业务上把需要有序的打到同⼀个partition
kafka性能调优
Broker参数配置
- 网络和io操作线程配置优化
broker处理消息的最大线程数 用于接收并处理网络请求的线程数,默认为3。一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1.
num.network.threads=3
broker处理磁盘IO的线程数 配置线程数量为cpu核数2倍,最大不超过3倍.
num.io.threads=8
- log数据文件刷盘策略(为了大幅度提高producer写入吞吐量,需要定期批量写文件。)
#每当producer写入10000条消息时,刷数据到磁盘 log.flush.interval.messages=10000
#每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
- 日志保留策略配置
当kafka server的被写入海量消息后,会生成很多数据文件,且占用大量磁盘空间,如果不及时清理,可能磁盘空间不够用,kafka默认是保留7天。
#保留三天,也可以更短
log.retention.hours=72
#段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(如果文件过小,则文件数量比较多,
#kafka启动时是单线程扫描目录(log.dir)下所有数据文件)
log.segment.bytes=1073741824
Producer优化
Message的缓冲区大小
buffer.memory:33554432 (32m)
#在Producer端用来存放尚未发送出去的Message的缓冲区大小。缓冲区满了之后可以选择阻塞发送或抛出异常,由block.on.buffer.full的配置来决定。
是否进行压缩
compression.type:none
有效值为none,gzip,snappy或lz4
Snappy压缩技术是Google开发的,它可以在提供较好的压缩比的同时,减少对CPU的使用率并保证好的性能,所以建议在同时考虑性能和带宽的情况下使用。
Gzip压缩技术通常会使用更多的CPU和时间,但会产生更好的压缩比,所以建议在网络带宽更受限制的情况下使用。
通过启用压缩功能,可以减少网络利用率和存储空间,这往往是向Kafka发送消息的瓶颈。
#默认发送不进行压缩,推荐配置一种适合的压缩算法,可以大幅度的减缓网络压力和Broker的存储压力。
在发送当前批次消息之前等待新消息的时间量
linger.ms:0
#Producer默认会把两次发送时间间隔内收集到的所有Requests进行一次聚合然后再发送,以此提高吞吐量,而linger.ms则更进一步,这个参数为每次发送增加一些delay,以此来聚合更多的Message。
每批处理的数据量
batch.size:16384 16k
#当多个消息被发送到同一个分区时,生产者会把它们一起处理。此配置设置用于每批处理使用的内存字节数batch.size指明了一次Batch合并后Requests总大小的上限。如果这个值设置的太小,可能会导致所有的Request都不进行Batch。
客户端会重新发送任何发送失败的消息的次数
retries
默认值为0,当设置为大于零的值,客户端会重新发送任何发送失败的消息。
注意,此重试与客户端收到错误时重新发送消息是没有区别的。
在配置max.in.flight.requests.per.connection不等于1的情况下,允许重试可能会改变消息的顺序,
因为如果两个批次的消息被发送到同一个分区,第一批消息发送失败但第二批成功,而第一批消息会被重新发送,则第二批消息会先被写入。注意此参数可能会改变消息的顺序性。
户端等待请求响应的最长时间
request.timeout.ms
此配置设置客户端等待请求响应的最长时间,默认为30000ms=30秒
如果在这个时间内没有收到响应,客户端将重发请求,如果超过重试次数将抛异常。
此配置应该比replica.lag.time.max.ms(broker配置,默认10秒)大,以减少由于生产者不必要的重试造成消息重复的可能性。
follower被踢出ISR的时间界限
replica.lag.time.max.ms 默认值为5000ms
在 follower 落后 leader 超过replica.lag.max.messages 条消息的时候,不会立马踢出ISR 集合,而是持续落后超过 replica.lag.time.max.ms 时间,才会被踢出,
这样就能避免流量抖动造成的运维问题,因为follower 在下一次fetch的时候就会跟上leader, 这样就也不用对 topic 的写入速度做任何的估计。
replica.lag.max.messages 为follower落后leader的次数。
Consumer优化
vim /opt/kafka/config/consumer.properties
num.consumer.fetchers:1
#启动Consumer的个数,适当增加可以提高并发度。
fetch.min.bytes:1
#每次Fetch Request至少要拿到多少字节的数据才可以返回。
#在Fetch Request获取的数据至少达到fetch.min.bytes之前,允许等待的最大时长。对应上面说到的Purgatory中请求的超时时间。
fetch.wait.max.ms:100
消费者是否自动提交偏移量
默认值是true,为了尽量避免重复数据和数据丢失,可以把它设置为false,
由自己控制合适提交偏移量,如果设置为true, 可以通过设置 auto.commit.interval.ms属性来控制提交的频率
enable.auto.commit
当一个consumer因某种原因退出Group时,进行重新分配partition后,同一group中的另一个consumer在读取该partition时,怎么能够知道上一个consumer该从哪个offset的message读取呢?
是如何保证同一个group内的consumer不重复消费消息呢?;这些数据还没有被消息完毕,Consumer就挂掉了,下一次进行数据fetch时,是否会从上次读到的数据开始读取,而导致Consumer消费的数据丢失吗?
为了做到这一点,当使用完poll从本地缓存拉取到数据之后,需要client调用commitSync方法(或者commitAsync方法)去commit 下一次该去读取 哪一个offset的message。
而这个commit方法会通过走网络的commit请求将offset在coordinator中保留,这样就能够保证下一次读取(不论进行了rebalance)时,既不会重复消费消息,也不会遗漏消息。
- 消费者长时间失效当前的偏移量已经过时并且被删除了
默认值是latest,也就是从最新记录读取数据(消费者启动之后生成的记录),另一个值是earliest,意思是在偏移量无效的情况下,消费者从起始位置开始读取数据。
auto.offset.reset
- 当消费者被认为已经挂掉之前可以与服务器断开连接的时间
session.timeout.ms
默认是3s,消费者在3s之内没有再次向服务器发送心跳,那么将会被认为已经死亡.此时,协调器将会出发再均衡,把它的分区分配给其他的消费者,
该属性与heartbeat.interval.ms紧密相关,该参数定义了消费者发送心跳的时间间隔,也就是心跳频率,一般要同时修改这两个参数,heartbeat.interval.ms参数值必须要小于session.timeout.ms,一般是session.timeout.ms的三分之一,
比如,session.timeout.ms设置成3min,那么heartbeat.interval.ms一般设置成1min,这样,可以更快的检测以及恢复崩溃的节点,
不过长时间的轮询或垃圾收集可能导致非预期的再均衡(有一种情况就是网络延迟,本身消费者是没有挂掉的,但是网络延迟造成了心跳超时,这样本不该发生再均衡,但是因为网络原因造成了非预期的再均衡),把该属性的值设置得大一些,可以减少意外的再均衡,不过检测节点崩愤-需要更长的时间。
- 服务器从每个分区里返回给消费者的最大字节数
它的默认值是lMB,也就是说,kafkaConsumer.poll() 方法从每个分区里返回的记录最多不超max.partitions.fetch.bytes 指定的字节
如果一个主题有20 个分区和5 个消费者,那么每个消费者需要至少4MB 的可用内存来接收记录,
在为消费者分配内存时,可以给它们多分配一些,因为如果群组里有消费者发生奔溃,剩下的消费者需要处理更多的分区
在设置该属性时,另一个需要考虑的因素是消费者处理数据的时间。消费者需要频繁调用poll()方法来避免会话过期和发生分区再均衡,
如果单次调用poll()返回的数据太多,消费者需要更多的时间来处理,可能无怯及时进行下一个轮询来避免会话过期。
如果出现这种情况, 可以把max.partitioin.fetch.bytes 值改小,或者延长会话过期时间。
- 消费者从服务器获取记录的最小字节数
broker收到消费者拉取数据的请求的时候,如果可用数据量小于设置的值,那么broker将会等待有足够可用的数据的时候才返回给消费者,这样可以降低消费者和broker的工作负载
- broker返回给消费者最小的数据量
而fetch.max.wait.ms设置的则是broker的等待时间,两个属性只要满足了任何一条,broker都会将数据返回给消费者
举个例子,fetch.min.bytes设置成1MB,fetch.max.wait.ms设置成1000ms,那么如果在1000ms时间内,如果数据量达到了1MB,broker将会把数据返回给消费者;
如果已经过了1000ms,但是数据量还没有达到1MB,那么broker仍然会把当前积累的所有数据返回给消费者
分区分配策略
Range:该策略会把主题的若干个连续的分区分配给消费者
Robin:该策略把主题的所有分区逐个分配给消费者
分区策略默认是:org.apache.kafka.clients.consumer.RangeAssignor=>Range策略
org.apache.kafka.clients.consumer.RoundRobinAssignor=>Robin策略
实现自定义分区
public class MyParatitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
//key不能空,如果key为空的会通过轮询的方式 选择分区
if(keyBytes == null || (!(key instanceof String))){
throw new RuntimeException("key is null");
}
//获取分区列表
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//以下是上述各种策略的实现,不能共存
//随机策略
return ThreadLocalRandom.current().nextInt(partitions.size());
//按消息键保存策略
return Math.abs(key.hashCode()) % partitions.size();
//自定义分区策略, 比如key为123的消息,选择放入最后一个分区
if(key.toString().equals("123")){
return partitions.size()-1;
}else{
//否则随机
ThreadLocalRandom.current().nextInt(partitions.size());
}
}
@Override
public void close() {
}
}
kafka高吞吐量追溯
在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节Socket转移到磁盘,通过内核空间保存副本,并在内核用户之间调用内核。
- 零拷贝技术
零拷贝(zero-copy)是实现主机或路由器等设备高速网络接口的主要技术;一般来说, 认为从网卡到用户空间的系统调用会经历两次或者两次半的copy过程.zero copy就是要消除这些copy过程.零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。

1.JVM向OS发出read()系统调用,触发上下文切换,从用户态切换到内核态。
2.从外部存储(如硬盘)读取文件内容,通过直接内存访问(DMA)存入内核地址空间的缓冲区。
3.将数据从内核缓冲区拷贝到用户空间缓冲区,read()系统调用返回,并从内核态切换回用户态。
4.JVM向OS发出write()系统调用,触发上下文切换,从用户态切换到内核态。
5.将数据从用户缓冲区拷贝到内核中与目的地Socket关联的缓冲区。
6.数据最终经由Socket通过DMA传送到硬件(如网卡)缓冲区,write()系统调用返回,并从内核态切换回用户态。
由下图可以看出少了一次数据拷贝的次数

异常问题处理
org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
- 执行如下测试生产者能力的命令时产生如上异常
kafka-producer-perf-test.sh --topic mytopic --num-records 1000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=wq1:9092,wq3:9092
- 查看Zookeeper选举状态
[root@wq3 bin]# zkServer.sh status
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
[root@wq1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
- 重启Kafka集群(判断为连接超时)
kafka-server-start.sh -daemon /opt/kafka/config/server.properties
- 查看生产能力
301271 records sent, 60133.9 records/sec (5.73 MB/sec), 1895.8 ms avg latency, 2412.0 max latency.