前言
虽然这是一个用CDH搭建起来的集群,本篇前半部分大概展示下CDH搭建过程,以及搭建好后它的样子是什么,但是主要侧重记录单独某一组件发挥的作用
CDH搭建步骤
- 下载ClouderaManager
点击进入下载界面 -
环境准备
- 各个主机名之间设置映射
- 关闭并禁用防火墙
- 关闭SELinux
- 设置SSH免密登陆(所有节点)
- 禁用透明大页(所有节点)
- 修改Linux swappiness参数(所有节点)
- 安装JDK(所有节点)要求使用指定版本的oracle-j2sdk1.8
- 上传JDBC依赖包(所有节点)
- 安装
- 安装MySQL(master节点)
- 安装Apache Httpd服务(master节点)
- 配置Cloudera Manager安装包yum源(master节点)
- 安装 Cloudera Manager(master节点)
原始数据信息表
后期的操作主要围绕下面这六张表的数据展开
| Products(产品表) | |||
| 列名称 | 类型 | 数量 | 描述 |
| productid | int | 10000 | 产品id |
| produceName | string | 10000 | 产品名 |
| supplier | int | 供应商 | |
| categoryID | int | 产品类型ID | |
| quantityPerUint | string | 每种产品的数量 | |
| unitPrice | double | 单价 | |
| Employee(员工表) | |||
| 列名称 | 类型 | 数量 | 描述 |
| employeeId | int | 10000 | 员工id |
| lastname | string | 10000 | 姓名 |
| firstName | string | 2000 | 名字 |
| title | string | 200 | 职位 |
| titleofCountry | string | 100 | |
| birthdate | date | 出生日期 | |
| hiredate | date | 入职时间 | |
| address | string | 住址 | |
| city | string | 100 | 城市 |
| region | string | 10 | 片区 |
| postalCode | string | 100 | 邮编 |
| country | string | 3 | 国家 |
| homePhone | string | 10000 | 家庭电话 |
| extension | string | 备注 | |
| photo | string | 头像 | |
| note | string | ||
| reportTo | int | 上级领导 | |
| salary | double | 薪水 | |
| custom(顾客表) | |||
| customerID | string | 1000000 | 客户id |
| companyName | string | 10000 | 公司名称 |
| contactName | string | 1000000 | 联系人姓名 |
| contactTile | string | 10000 | 联络人职位 |
| address | string | 10000 | 地址 |
| city | string | 100 | 城市 |
| regdate | Date | 客户注册时间 | 客户注册时间 |
| region | string | 10 | 客户区域 |
| postalcode | string | 100 | 邮政编码 |
| country | string | 3 | 国家 |
| phone | string | 1000000 | 电话 |
| fax | string | 1000000 | 传真 |
| order(订单) | |||
| orderid | Int | 10000000 | 订单id |
| customerID | string | 1000000 | 客户id |
| employID | string | 1000 | 雇员id |
| orderdate | date | 订单生成时间 | |
| requiredDate | date | 需用日期 | |
| shippedDate | date | 发货日期 | |
| shipvia | int | 发货方式 | |
| freight | double | 运费 | |
| shipname | string | 100 | 运输方式 |
| shipadress | string | 100000 | 发货地址 |
| shipcity | string | 100 | 发货城市 |
| shipregion | string | 10 | 发货区域 |
| shippostalcode | string | 100000 | 发货邮政编码 |
| shipcountry | string | 11 | 发货国家 |
| orderdatail(订单详情) | |||
| 列名称 | 类型 | 数量 | 描述 |
| orderid | int | 10000000 | 订单id |
| productId | int | 10000 | 产品id |
| unitPrice | double | 单价 | |
| quantity | int | 数量 | |
| discount | double | 折扣 | |
| category(产品目录) | |||
| 列名称 | 类型 | 数量 | 描述 |
| categoryID | string | 100 | 产品类别ID |
| categoryName | string | 100 | 产品类别名称 |
集群配置情况


– cdh0051
[root@cdh0051 ~]# jps
3152 HeadlampServer
3153 Main
1651 Main
108244 Jps
3386 EventCatcherService
3150 Main
3151 AlertPublisher
- cdh0052
[root@cdh0052 ~]# jps
3009 ResourceManager
2641 EmbeddedOozieServer
2642 Application
3011 DataNode
2645 QuorumPeerMain
15366 Jps
3035 NodeManager
2639 NameNode
- cdh0053
[root@cdh0053 ~]# jps
2721 SecondaryNameNode
45733 Jps
2744 DataNode
2713 NodeManager
2633 Kafka
2636 QuorumPeerMain
- cdh0054
[root@cdh0054 ~]# jps
69521 Jps
2625 Kafka
2915 NodeManager
2627 HistoryServer
2708 DataNode
2710 QuorumPeerMain
2631 RunJar
2632 RunJar
1、需求分析(梳理表结构,梳理其度量)
度量 Metric
客户数(Customer 数量)
活跃率(活跃客户数/总客户数;活跃定义:一周内下过订单;)
销售额(orderdetails 表内的unit price * quantity – discount)
订单量(order 的数量)
销售量(产品所有order 的quantity 的总和)
销售额Top100(片区)
销售额Topn(员工)
销售额Topn(产品)
维度 Dimension
时间(如按时间切销售额等指标)
员工(如分析不同员工促成的销售额等指标)
销售片区(分析不同销售片区促成的销售额等指标)
产品(分析不同产品的销售额等指标)
产品类别(分析不同类别产品的销售额等指标)
- 以下需求是一个建议,可以从很多角度对数据进行分析
- 昨日销售额多少?
- 昨日新增客户多少?
- 本周总共新增客户多少?
- 目前平台活跃客户率如何?
- 平台件均价多少?
- 本周平台最畅销的产品是什么?意图(度量):最畅销产品Top-1维度:时间、(销量)
- 最畅销产品排名前十是?
2、集群架构设计(使用那些组件、所有组件和机器的对应关系)
Cloudera Manager:http://192.168.3.51:7180/
Namenode http://192.168.3.52:9870/
Hue http://192.168.3.53:8889/
cdh0051
| 组件/角色 | 作用 |
| Alert Publisher | 为特定类型的事件生成和提供警报 |
| Event Server | 聚合 relevant Hadoop 事件并将其用于警报和搜索 |
| Host Monitor | 收集有关主机的运行状况和指标信息 |
| Reports Manager | 生成报告,它提供用户、用户组和目录的磁盘使用率的历史视图,用户和 YARN 池的处理活动,以及 HBase 表和命名空间。 |
| Service Monitor | 收集有关服务的运行状况和指标信息以及 YARN 和 Impala 服务中的活动信息 |
cdh0052
| 组件/角色 | 作用 |
| Flume | 1)提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务, |
| DataNode | 文件系统的工作节点,根据需要存储和检索数据块,并且定期向namenode发送他们所存储的块的列表。 |
| NameNode | Namenode存放文件系统树及所有文件、目录的元数据 |
| hive/Gateway | 它们充当了告诉客户端配置应该放置在哪里。 |
| Oozie Server | Oozie是一个工作流调度器系统,用于管理Apache Hadoop作业。 |
| spark/Gateway | spark gateway是用于接收cloudera管理的应用 |
| YARN/JobHistoryServer | 历史服务器,管理者可以通过历史服务器查看已经运行完成的Mapreduce作业记录,比如用了多少个Map、多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。 |
| YARN/NodeManager | NodeManager管理一个YARN集群中的每一个节点。比如监视资源使用情况( CPU,内存,硬盘,网络),跟踪节点健康等。 |
| YARN/ResourceManager | ResourceManager是Yarn集群主控节点,负责协调和管理整个集群(所有NodeManager)的资源。 |
| ZooKeeper Server | 配置管理,名字服务,提供分布式同步以及集群管理 |
cdh0053
| 组件 | 作用 |
| DataNode | |
| hive/Gateway | |
| Metastore Server | |
| HiveServer2 | |
| Kafka Broker | |
| spark/Gateway | |
| History Server | |
| NodeManager | |
| ZooKeeper Server |
cdh0054
| 组件 | 作用 |
| DataNode | |
| SecondaryNameNode | 首先,它定时到NameNode去获取edit logs,并更新到fsimage上。 一旦它有了新的fsimage文件,它将其拷贝回NameNode中。 NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。 |
| hive/Gateway | |
| Load Balancer | LoadBalancer 可以将来自客户端的请求分发到不同的服务器 |
| History Server | Spark应用程序在运行完应用程序之后,将应用程序的运行信息写入指定目录(指定日志记录的目录),而Spark history server可以将这些运行信息装载并以web的方式供用户浏览(展示)。 |
| Kafka Broker | 缓存代理,Kafka集群中的一台或多台服务器统称broker. |
| spark/Gateway | |
| NodeManager | |
| ZooKeeper Server |
3、数据处理流程设计(数据流程图)
处理前先了解各个组件的功能
| 组件 | 作用 | 原理 |
| Flume | 实时进行数据收集 | 事件作为Flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(传输中的数据)和一个可选头部构成.对于于每一个Agent来说,它就是一共独立的守护进程。 Agent主要由:source,channel,sink三个组件组成. Source:从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal。 channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase. |
| Kafka | 是一个可持久化的分布式的消息队列 | kafka和flume都是日志系统,kafka是分布式消息中间件,自带存储,提供push和pull存取数据功能。flume分为agent(数据采集器),collector(数据简单处理和写入),storage(存储器)三部分,每一部分都是可以定制的。 kafka做日志缓存应该是更为合适的,但是 flume的数据采集部分做的很好,可以定制很多数据源,减少开发量。 Cloudera 建议如果数据被多个系统消费的话,使用kafka;如果数据被设计给Hadoop使用,使用Flume。 broker 经纪人(代理人):kafka服务的java进程实例、broker之间没有主从关系,他们是平等的节点关系、broker需要依靠zookeeper集群进行通信 topic 主题:于kafka来说 topic用来对消息进行归类、生产者写入数据和消费者读取数据时,都需要指定topic partition 分区:topic是一个逻辑概念,他对于kafka集群来说是全局的、topic真正存消息时,是将消息写到特定目录的特定文件中、特定目录就是 分区、特定文件就是 分区这个目录下的文件、分区的命名方式(文件夹)的命名方式 主题名-分区编号 topic-1 offset偏移量:在kafka的每个分区中,使用offset来对消息进行编号,每个分区内部,offset是单调递增且唯一的、因为offset由分区来维护,所以不同分区可能会有相同的offset replication 副本:某个分区的数据在集群中存多少份、每个分区都可以设置多个副本、注意! 副本的数量不能超过broker数量、同一个主题的同一个分区的不同副本之间,会选举出来一个leader,其他的副本作为follower、客户端进行topic的读写时是与leader进行通信、follower负责同步leader的数据 producer 生产者:负责往kafka的topic中写入数据、同一个topic可以有多个生产者 同一个生产者也可以同时写入多个topic consumer 消费者:负责从kafka的topic中读取数据consumer会记录自己读取的offset,下次启动时可以从上次的位置继续读取数据、也可以自定义offset从特定位置开始消费数据 cousumer group 消费者组、同组的消费者,会共享offset记录 |
| hive | 用于解决海量结构化日志的数据统计。 | Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 本质是:将HQL转化成MapReduce程序 Hive处理的数据存储在HDFS Hive分析数据底层的实现是MapReduce 执行程序运行在YARN上 Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。 内部表(管理表):ive会(或多或少地)控制着数据的生命周期 外部表:因为表是外部表,所有Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉 分区表:分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。 |
| spark | 是一种快速、通用、可扩展的大数据分析引擎 | Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。 Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。 Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。 Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。 集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。 |
| HDFS | 分布式文件管理系统 | HDFS基于这样的一个假设:最有效的数据处理模式是一次写入、多次读取数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 |
| Yarn | 资源协调者 | YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。 |
| Zookeeper | 分布式服务框架 | 它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。 现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。 |
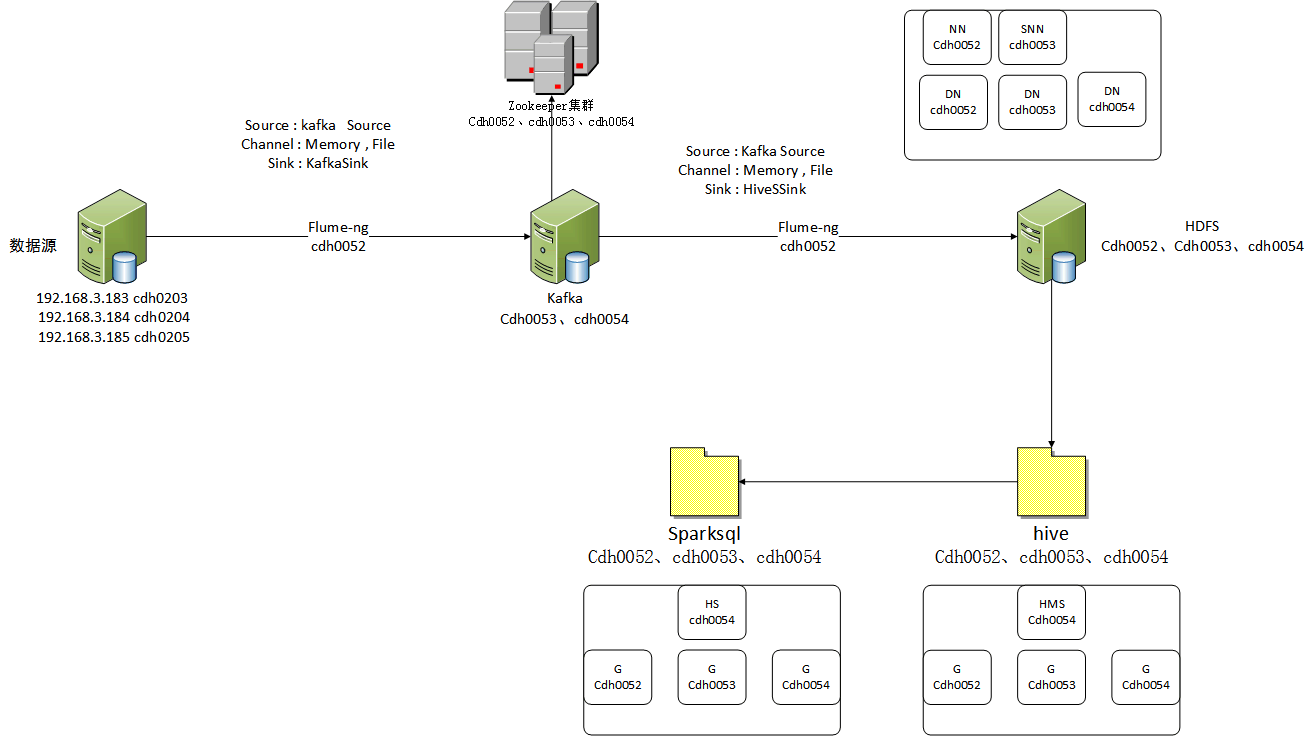
- 通过flume把一个kafka集群的数据采集到自己的kafka集群
点击查看flume官方配置文件
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#file-channel
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# configure source
# source 为kafka类型
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
//批量大小-一次
a1.sources.r1.batchSize = 5000
//批处理时间-每隔多少毫秒处理的时间
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = cdh0203:9092,cdh0204:9092,cdh0205:9092
/topic
a1.sources.r1.kafka.topics = topic01-categories
#1earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
a1.sources.r1.kafka.consumer.auto.offset.reset = earliest
//组id,名字随意,同组可消费一个topic
a1.sources.r1.kafka.consumer.group.id = ds001
# configure sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
//自己集群的topic,但尽量与数据源topic一致
a1.sinks.k1.kafka.topic = topic01-categories
a1.sinks.k1.kafka.bootstrap.servers = cdh0053:9092,cdh0054:9092
a1.sinks.k1.kafka.flumeBatchSize = 2000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
a1.sinks.kafka-sink.kafka.producer.batch.size = 1048576
# configure channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacity = 800000
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 把本地kafka集群的数据传到hdfs上
-
设计hive仓库
- 数据仓库与数据库的区别
数据库是面向事物的,它是针对具体业务在数据库联机的日常操作,数据量小
数据仓库是面向处理的,它是针对具体业务在数据库联机的日常操作,数据量大
数据仓库标准上可以分为四层:ODS(临时存储层)、PDW(数据仓库层)、DM(数据集市层)、APP(应用层)。
ODS:一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。
PDW:这一层的数据一般是遵循数据库第三范式的
DW:从数据的时间跨度来说,通常是PDW层的一部分,主要的目的是为了满足用户分析的需求
APP:这层数据是完全为了满足具体的分析需求而构建的数据
- 为什么要对数据仓库分层:
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;
2如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大
3通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
六张表之间的关系

订单表
MSCK REPAIR TABLE命令主要是用来解决通过hdfs dfs -put或者hdfs api写入hive分区表的数据在hive中无法被查询到的问题。
CREATE EXTERNAL TABLE IF NOT EXISTS orders_ods_t
(
orderid INT COMMENT "订单id",
customerID INT COMMENT "客户id",
employID INT COMMENT "员工id",
orderdate DATE COMMENT "订单生成时间",
requiredDate DATE COMMENT "需用日期",
shippedDate DATE COMMENT "发货日期",
shipvia INT COMMENT "发货方式",
freight DOUBLE COMMENT "运费",
shipname STRING COMMENT "运输方式",
shipadress STRING COMMENT "发货地址",
shipcity STRING COMMENT "发货城市",
shipregion STRING COMMENT "发货区域",
shippostalcode STRING COMMENT "发货邮政编码",
shipcountry STRING COMMENT "发货国家"
)
COMMENT "订单表"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/orders_ods_t';
MSCK REPAIR TABLE orders_ods_t;
订单详情表
CREATE EXTERNAL TABLE IF NOT EXISTS orderdetails_ods_t
(
orderid INT COMMENT "订单id",
productId INT COMMENT "产品id",
unitPrice DOUBLE COMMENT "单价",
quantity INT COMMENT "数量",
discount DOUBLE COMMENT "折扣"
)
COMMENT "订单详情"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/orderdetails_ods_t';
MSCK REPAIR TABLE orderdetails_ods_t;
顾客表
CREATE EXTERNAL TABLE IF NOT EXISTS customers_ods_t
(
customerID INT COMMENT "客户id",
companyName STRING COMMENT "公司名称",
contactName STRING COMMENT "联系人姓名",
contactTile STRING COMMENT "联络人职位",
address STRING COMMENT "地址",
city STRING COMMENT "城市",
regdate DATE COMMENT "客户注册时间",
region STRING COMMENT "客户区域",
postalcode STRING COMMENT "邮政编码",
country STRING COMMENT "国家",
phone STRING COMMENT "电话",
fax STRING COMMENT "传真"
)
COMMENT "顾客表"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/customers_ods_t';
MSCK REPAIR TABLE customers_ods_t;
员工表
CREATE EXTERNAL TABLE IF NOT EXISTS employees_ods_t
(
employeeId INT COMMENT "员工id",
lastname STRING COMMENT "员工名",
firstName STRING COMMENT "员工姓",
title STRING COMMENT "头衔",
titleofCountry STRING COMMENT "所属国家",
birthdate DATE COMMENT "出生日期",
hiredate DATE COMMENT "入职时间",
address STRING COMMENT "地址",
city STRING COMMENT "城市",
region STRING COMMENT "片区",
postalCode STRING COMMENT "邮编",
country STRING COMMENT "国籍",
homePhone STRING COMMENT "电话",
extension STRING COMMENT "附加",
photo STRING COMMENT "照片",
note STRING COMMENT "注意",
reportTo INT COMMENT "上级领导",
salary DOUBLE COMMENT "工资"
)
COMMENT "员工表"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/employees_ods_t';
MSCK REPAIR TABLE employees_ods_t;
产品表
CREATE EXTERNAL TABLE IF NOT EXISTS products_ods_t
(
productid INT COMMENT "产品id",
produceName STRING COMMENT "产品名",
supplier INT COMMENT "供应商",
categoryID INT COMMENT "产品类型ID",
quantityPerUint STRING COMMENT "每种产品的数量",
unitPrice DOUBLE COMMENT "单价"
)
COMMENT "产品表"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/products_ods_t';
MSCK REPAIR TABLE products_ods_t;
SELECT * FROM products_ods_t LIMIT 5;
partitioned by (dt string,type string) //制定分区
row format delimited fields terminated by '\t' //指定字段分隔符为tab
collection items terminated by ',' //指定数组中字段分隔符为逗号
map keys terminated by ':' //指定字典中KV分隔符为冒号
lines terminated by '\n' //指定行分隔符为回车换行
stored as textfile //指定存储类型为文件
产品目录表
CREATE EXTERNAL TABLE IF NOT EXISTS category_ods_t
(
categoryID INT COMMENT "产品类别ID",
categoryName STRING COMMENT "产品类别名称"
)
COMMENT "产品目录表"
partitioned by (year string,month string,day string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/category_ods_t';
加载hdfs数据到hive
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/order' overwrite into table orders_ods_t partition (yt="2021",mt="03",dt="29");
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/orderdetail' overwrite into table orderdetails_ods_t partition (yt="2021",mt="03",dt="29");
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/custom' overwrite into table customers_ods_t partition (yt="2021",mt="03",dt="29");
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/employee' overwrite into table employees_ods_t partition (yt="2021",mt="03",dt="29");
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/products' overwrite into table products_ods_t partition (yt="2021",mt="03",dt="29");
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/categories' overwrite into table category_ods_t partition(year="2021",month="03",day="29");
- 写HiveSQL语句处理数据
最畅销商品排名前100的是?(默认是升序)
create table p100
as
select
b.producename ,
sum(a.unitprice*quantity*discount)
as c
from shoppingmall.orderdetails_ods_t
as a
inner join
shoppingmall.products_ods_t
as b
on a.productid=b.productid
group by b.producename
order by c limit 100;
- sqoop导数据到MySQL
sqoop安装位置
/opt/cloudera/parcels/CDH-6.3.2-\1.cdh6.3.2.p0.1605554/lib/sqoop/
配置文件
sqoop export \
--connect jdbc:mysql://192.168.3.51:3306/hive \
--username root \
--password 123456 \
--table north \
--export-dir /user/hive/warehouse/app_database.db/north \
--fields-terminated-by '\001' \
--m 1
如果出现这种错误,则是数据库相关的错误,比如数据库字段不对,编码格式等;
ERROR tool.ExportTool: Error during export:
Export job failed!
at org.apache.sqoop.mapreduce.ExportJobBase.runExport(ExportJobBase.java:445)
at org.apache.sqoop.manager.SqlManager.exportTable(SqlManager.java:931)
at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:80)
at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:99)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
- QuickBI上展示的数据
每个片区销售额排前10的商品
create table sourth
as
select
b.producename ,
sum(a.unitprice*quantity*discount)
as c
from
pdw_database.orderdetails_pdw_t
as a
inner join
pdw_database.products_pdw_t
as b
on a.productid=b.productid
inner join
pdw_database.orders_pdw_t
as e
on a.orderid=e.orderid
where e.shipregion='South'
group by b.producename
order by c
limit 10