一、是什么
- 官网给出的解释
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
点击进入Hive官网
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析,但是Hive不支持实时查询。
数据仓库与数据库的异同
- 数据仓库是什么
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库标准上可以分为四层:ODS(临时存储层)、PDW(数据仓库层)、DM(数据集市层)、APP(应用层)。
- ODS层
Operate Data Store操作数据存储,为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。一般来说ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。从数据粒度上来说ODS层的数据粒度是最细的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存;
- PDW层
为数据仓库层,PDW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。这一层的数据一般是遵循数据库第三范式的,其数据粒度通常和ODS的粒度相同。在PDW层会保存BI系统中所有的历史数据,例如保存10年的数据。
- DM层
为数据集市层,这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是PDW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。从数据的广度来说,仍然覆盖了所有业务数据。
- APP层
为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。从数据的广度来说,则并不一定会覆盖所有业务数据,而是DM层数据的一个真子集,从某种意义上来说是DM层数据的一个重复。从极端情况来说,可以为每一张报表在APP层构建一个模型来支持,达到以空间换时间的目的数据仓库的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
- 数据仓库与数据库的区别
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。
- 相同之处
hive数仓在操作时写的hive SQL语句与SQL语句基本上没什么区别,所以只要对MySQL有些了解,使用hive数仓时也没啥障碍,就是你从概念上有个认识就行。
二、怎么用
怎么安装到centos7系统上
首先你要装上MySQL,hdfs也启动了
我的hive安装目录为 /opt/hive-1.2.2/
1. vim hive-env.sh
export HADOOP_HOME=/opt/hadoop-2.7.7
export HIVE_CONF_DIR=/opt/hive-1.2.2/conf
export JAVA_HOME=/opt/jdk1.8
export HIVE_HOME=/opt/hive-1.2.2
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 设置Hive保存元数据使用的Mysql数据库 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!-- 安装数据库的那个机器 -->
<value>jdbc:mysql://wq2:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<!-- 用户 -->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<!-- 密码 -->
<name>javax.jdo.option.ConnectionPassword</name>
<value>specialWu7.</value>
</property>
<!-- hive客户端打印标题信息 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- hive客户端打印当前数据库名 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
vim /etc/profile
PATH前必须有这个美元符号,HIVE_HOME前也必须有美元符号,修改系统文件的时候一定要注意这块,不然容易出问题(特别说明下因为这个dollar符在我文章中显示不出来,加上后就消失了)
`export HIVE_HOME = /opt/hive-1.2.2
export PATH = PATH:HIVE_HOME/bin
#记得执行这个使之生效
source /etc/profile`
如果上面没加dollar符,那么所有基本命令无法执行
[root@wq1 etc]# ls
bash: ls: 未找到命令...
相似命令是: 'lz'
[root@wq1 etc]# lz
bash: lz: 未找到命令...
相似命令是: 'ls'
[root@wq1 etc]# ss
bash: ss: 未找到命令...
相似命令是::
'ss'
'sz'
[root@wq1 etc]# ss
bash: ss: 未找到命令...
相似命令是::
解决命令失效办法
在命令行中输入
PATH=/bin:/usr/bin
- 将自己Java项目的 mysql-connector-java-5.1.35.jar 放到hive安装目录下的lib文件夹中
hive脚本的执行方式
hive后组合的命令及含义
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
-h <hostname> connecting to Hive Server on remote host
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-p <port> connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
- hive控制台执行
hive> set mapred.job.queue.name=pms;
hive> select page_name, tpa_name from pms.pms_exps_prepro limit 2;
- hive -e “SQL”执行
hive -e "select page_name, tpa_name from pms.pms_exps_prepro limit 2;"
- hive -f SQL文件执行
date=2015-10-22
hive -f test.sql --hivevar date=$date
把所有数据库下的表字段保存到一个文件夹中的脚本
#!/bin/bash
hive -e "show databases ;" > databases.txt
i=1
cat databases.txt |while read db
do
hive -e "use db;show tables;">i.txt
sleep 3
cat i.txt |while read eachline
do
hive -e "usedb;select * from eachline limit" >>tablesDDL.txt
done
i=(($i+1))
done
SQL语句范例
drop table if exists pms.pms_exps_prepro;
create table pms.pms_exps_prepro as
select
a.provinceid,
a.cityid,
a.ieversion,
a.platform,
'${date}' as ds
from track_exps a;
hive sql语句
在写hiveSQL语句前首先了解其特殊的部分在哪
- Hive没有delete和update。
- Hive不支持等值连接
#SQL
select * from dual a,dual b where a.key = b.key
#hive SQL
select * from dual a join dual b on a.key = b.key
- 在HiveQL中,对分号的识别没有那么智慧
#sql
select concat(';',key) from dual;
#hive sql使用分号的八进制的ASCII码进行转义
select concat('\073',key) from dual;
- Hive不支持将数据插入现有的表或分区中
#仅支持覆盖重写整个表
INSERT OVERWRITE TABLE t1 ;
- hive支持嵌入mapreduce程序,来处理复杂的逻辑
FROM (
MAP doctext USING 'python wc_mapper.py' AS (word, cnt)
FROM docs
CLUSTER BY word
) a
REDUCE word, cnt USING 'python wc_reduce.py';
- hive支持将转换后的数据直接写入不同的表,还能写入分区、hdfs和本地目录
INSERT OVERWRITE TABLE t2
SELECT t3.c2, count(1)
FROM t3
WHERE t3.c1 <= 20
GROUP BY t3.c2
INSERT OVERWRITE DIRECTORY '/output_dir'
SELECT t3.c2, avg(t3.c1)
FROM t3
WHERE t3.c1 > 20 AND t3.c1 <= 30
GROUP BY t3.c2
- HQL不支持行级别的增、改、删,所有数据在加载时就已经确定,不可更改
写hive sql语句
- 创建表
Hive默认的分隔符是\001
该表为外部表按照年月日进行分区,数据来源hdfs上,指定字段分隔符为制表符’\t’
CREATE EXTERNAL TABLE IF NOT EXISTS orders_ods_t
(
orderid INT COMMENT "订单id",
customerID INT COMMENT "客户id",
employID INT COMMENT "员工id",
shipcountry STRING COMMENT "发货国家"
)
COMMENT "订单表"
partitioned by (yt string,mt string,dt string)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/ods_database.db/orders_ods_t';
STORED AS TEXTFILE;
MSCK REPAIR TABLE orders_ods_t;
- 创建分桶表
对于分桶表是不能直接使用load data的,可以先建个中间表导入数据再load到中间,智慧从这个中间表拿到分桶表
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
CREATE EXTERNAL TABLE test_bucket (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期',
t_start_date STRING COMMENT '生效时间',
t_end_date STRING COMMENT '最后更改时间'
)
COMMENT '分桶表练习'
clustered by(user_num)
sorted by(user_num DESC)
into 4 buckets
LOCATION '/user/hive/warehouse/test.db/test_bucket';
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
insert into table test_bucket select user_num,mobile,reg_date,t_start_date,t_end_date from test_bucket_tmp1 distribute by(user_num) sort by(user_num asc);
- 查看表信息
describe formatted table_name test;
- 把hive表数据导入到hdfs上
insert overwrite directory '/root/hive_test/1.txt' select * from test;
- 把hdfs的数据映射到hive表中上
LOAD DATA INPATH 'hdfs://wq1:9000/source-six/categories' into table category_ods_t partition (yt="2020",mt="10",dt="26");;
hive的文件格式及选用
- 存储类型
面向行:同一行的数据存储在一起,即连续存储。SequenceFile,TEXTFILE 。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。
面向列:整个文件被切割为若干列数据,每一列数据一起存储。Parquet , RCFile,ORCFile。面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处于行的一小部分字段的情况。但是这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。同时不适合流式写入,因为一旦写入失败,当前文件无法恢复,而面向行的数据在写入失败时可以重新同步到最后一个同步点,所以Flume采用的是面向行的存储格式。
如果为textfile的文件格式,直接load就OK,不需要走MapReduce;如果是其他的类型就需要走MapReduce了,因为其他的类型都涉及到了文件的压缩,这需要借助MapReduce的压缩方式来实现。
压缩比:ORC > Parquet > RCFILE > Sequencefile > textFile(textfile没有进行压缩)数据压缩比例上ORC最优,相比textfile节省了50倍磁盘空间
查询速度:ORC > Parquet > RCFILE > Sequencefile > textFile
工作中原始日志写入hive的存储格式都采用ORC或者parquet格式
- TEXTFILE
TextFile文件不支持块压缩,默认格式,数据不做压缩,磁盘开销大,数据解析开销大,属于行式存储。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
- SEQUENCEFILE
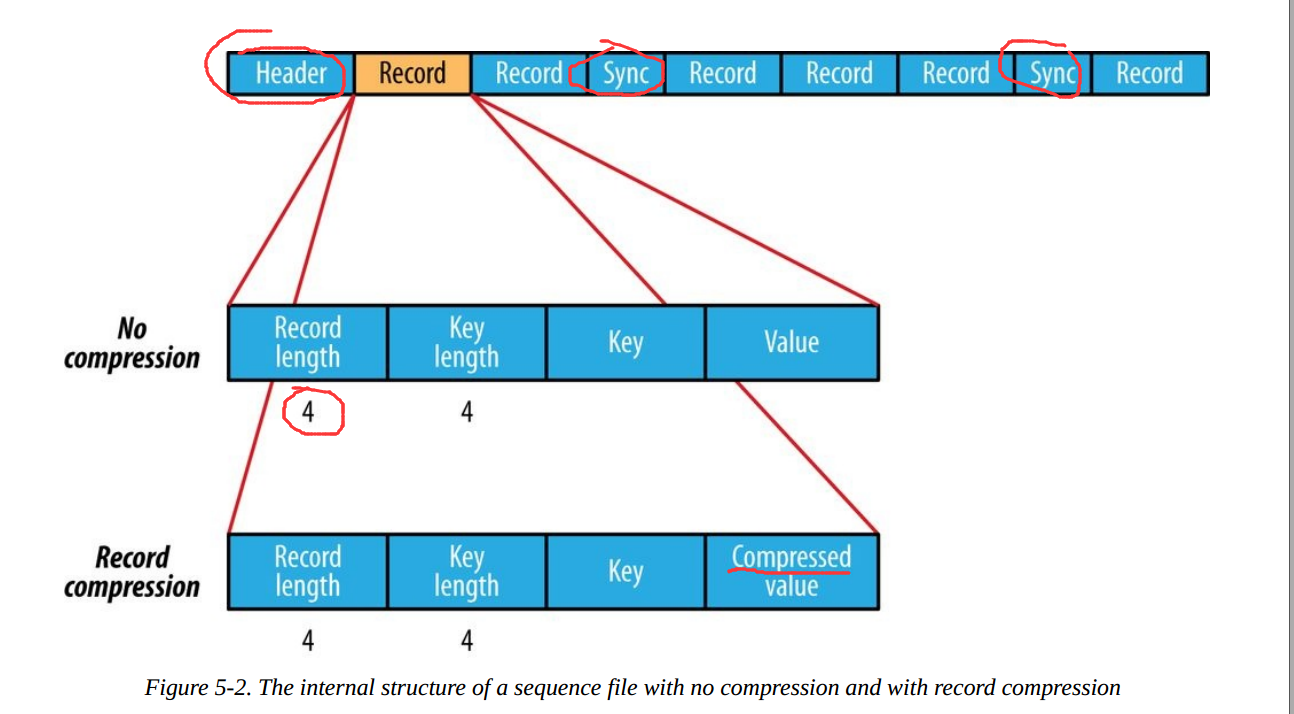
行式存储,SequenceFile是Hadoop API提供的一种二进制文件支持,,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。优势是文件和hadoop api中的MapFile是相互兼容的
- RCFILE
Record Columnar File,列式存储格式文件 Hive0.6以后开始支持,这种类型的文件先将数据按行划分成Row Group,在Row Group内部,再将数据按列划分存储。存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
- ORC
Optimized Record Columnar File,列式存储格式文件,比RCFILE有更高的压缩比和读写效率,Hive0.11以后开始支持,其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置.
- 三种设置orcfile的命令,同样适用设置其他格式的文件
#创表时
CREATE TABLE ... STORED AAS ORC
#修改表结构时
ALTER TABLE ... SET FILEFORMAT ORC
#设置表的参数时
SET hive.default.fileformat=ORC
- PARQUET
列出存储格式文件,Hive0.13以后开始支持
hive中的几种表
- 内部表(受控表):当删除内部表的时候,hdfs上的数据以及元数据都会被删除。
- 外部表:当删除外部表的时候,HDFS上的数据不会被删除,但是元数据会被删除。
- 临时表(测试环境):在当前会话期间内存在,会话结束自动消失,生命周期随之session。
- 分区表:将一批数据分成多个目录来存储。
- 分桶表:桶的概念就是MapReduce的分区的概念
hive误删内部表如何恢复
查找hive表的存储位置并查看表文件大小及分区文件名
hive (default)> show create table testhive;
OK
createtab_stmt
CREATE TABLE `testhive`(
`year` string,
`id` int,
`yearone` int,
`c1` int,
`c2` int,
`c3` int,
`c4` int,
`c5` int,
`c6` int,
`c7` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://wq1:9000/user/hive/warehouse/testhive'
TBLPROPERTIES (
'transient_lastDdlTime'='1603707783')
Time taken: 0.212 seconds, Fetched: 21 row(s)
hdfs回收站时间设置
#单位:分钟
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
自定义回收站逻辑
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Trash;
public class RMFile {
private final static Log log = LogFactory.getLog(RMFile.class);
private final static Configuration conf = new Configuration();
/**
* Delete a file/directory on hdfs
* @param path
* @param recursive
* @return
* @throws IOException
*/
public static boolean rm(FileSystem fs, Path path, boolean recursive)
throws IOException {
log.info("rm: " + path + " recursive: " + recursive);
boolean ret = fs.delete(path, recursive);
if (ret)
log.info("rm: " + path);
return ret;
}
/**
* Delete a file/directory on hdfs,and move a file/directory to Trash
* @param fs
* @param path
* @param recursive
* @param skipTrash
* @return
* @throws IOException
*/
public static boolean rm(FileSystem fs, Path path, boolean recursive,
boolean skipTrash) throws IOException {
log.info("rm: " + path + " recursive: " + recursive+" skipTrash:"+skipTrash);
if (!skipTrash) {
Trash trashTmp = new Trash(fs, conf);
if (trashTmp.moveToTrash(path)) {
log.info("Moved to trash: " + path);
return true;
}
}
boolean ret = fs.delete(path, recursive);
if (ret)
log.info("rm: " + path);
return ret;
}
public static void main(String[] args) throws IOException {
conf.set("fs.default.name", "hdfs://data2.kt:8020/");
FileSystem fs = FileSystem.get(conf);
RMFile.rm(fs,new Path("hdfs://data2.kt:8020/test/testrm"),true,false);
}
}
三、核心问题
抽样
select * from table_name order by rand() limit 100;
create table able_name1 as select * from able_name tablesample(10 percent);
select * from able_name2 tablesample(bucket 1 out of 10 on rand())
实例
查询成绩前三名
select class, name, score
from test_score a
where (select count(*) from test_score where class = a.class and a.score < score) < 3
order by a.class, a.score desc;
#fa2
select class, name, score
from (select class, score, name,
rank() over (partition by class order by score desc ) as rownum
from test_score)
where rownum < 4;
展示出最大连续登陆天数(每天可能会登陆多次)
user_num mobile
ss11 2021-04-01
ss11 2021-04-02
ss11 2021-04-03
ss11 2021-04-05
select
tongji.user_num,tongji.start_day,tongji.end_day,max(tongji.continue_days)
from
(
select x.user_num,min(x.pt_day) start_day,max(x.pt_day) end_day,count(*) continue_days
from
(
select a.user_num, to_date(a.mobile) pt_day,row_number()over (partition by a.user_num order by to_date(a.mobile)) rn
from(select distinct user_num,mobile from user_login_test) a) x group by x.user_num,date_sub(x.pt_day,x.rn-1)
) tongji;
报错待解决上面语句
Error while compiling statement: FAILED: SemanticException [Error 10025]: line 2:0 Expression not in GROUP BY key 'user_num'
如何解决数据倾斜的问题?
- 数据倾斜是hive调优面临的重要原因,调优前首先明确什么是数据倾斜,数据倾斜表现为map端已经完成100%,但是reduce端一直处于99%的状态。
- 大小表join时的数据倾斜
- group by
- count(distinct)
- 倾斜原因:
map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
(1)key分布不均匀;
(2)业务数据本身的特性;
(3)建表时考虑不周;
(4)某些SQL语句本身就有数据倾斜;
如何避免:对于key为空产生的数据倾斜,可以对其赋予一个随机值。
- 解决方案
- 参数调节:
#Map 端部分聚合,相当于Combiner
hive.map.aggr = true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。
第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的
第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作
hive.groupby.skewindata=true
- SQL 语句调节
- 大小表Join:
使用map join让小的维度表(1000 条以下的记录条数)先进内存。在map端完成reduce.
- 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null 值关联不上,处理后并不影响最终结果。
- count distinct大量相同特殊值:
count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
- 遇到需要进行join的但是关联字段有数据为null,如表一的id需要和表二的id进行关联,null值的reduce就会落到一个节点上
解决方法1:子查询中过滤掉null值,id为空的不参与关联
select a.user_id, a.order_id, b.user_id
from table_a a join table_b b
on (case when a.user_is is null then concat('hive', rand()) else a.user_id end) = b.user_id
解决方法2:用case when给空值分配随机的key值(字符串+rand())
- 不同数据类型关联产生数据倾斜
张表s8的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。s8的日志中有字符串商品id,也有数字的商品id,类型是string的,但商品中的数字id是bigint的。猜测问题的原因是把s8的商品id转成数字id做hash来分配reduce,所以字符串id的s8日志,都到一个reduce上了,解决的方法验证了这个猜测。
解决方法:把数字类型转换成字符串类型
- 当HiveQL中包含count(distinct)时
如果数据量非常大,执行如select a,count(distinct b) from t group by a;类型的SQL时,会出现数据倾斜的问题。
解决方法:使用sum…group by代替。如select a,sum(1) from (select a, b from t group by a,b) group by a;
请说明hive中 Sort By,Order By,Cluster By,Distrbute By各代表什么意思?
order by:会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:不是全局排序,其在数据进入reducer前完成排序。
distribute by:按照指定的字段对数据进行划分输出到不同的reduce中。
cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。
Hive内部表和外部表的区别?
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
转换日期的函数
def dateFormat(date: String) = {
val parser = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US)
val formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
formatter.format(parser.parse(date))
}
说说对Hive桶表的理解
桶表是对数据进行哈希取值,然后放到不同文件中存储。
数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。
桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
- 分区表与分桶表的区别
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中
Hive sql语句提交后执行过程
首先看转换过程,再展示执行过程
Hive的HSQL转换为MapReduce的过程
SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer: 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan:遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
job_1604020633149_0009
INFO : Compiling command(queryId=hive_20201116200245_6ca5200e-1ea5-41ef-8048-ab1b47d4e07e): SELECT *,row_number() OVER(PARTITION BY c ORDER BY c DESC)as tn FROM east
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:east.producename, type:string, comment:null), FieldSchema(name:east.c, type:double, comment:null), FieldSchema(name:tn, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20201116200245_6ca5200e-1ea5-41ef-8048-ab1b47d4e07e); Time taken: 0.122 seconds
INFO : Executing command(queryId=hive_20201116200245_6ca5200e-1ea5-41ef-8048-ab1b47d4e07e): SELECT *,row_number() OVER(PARTITION BY c ORDER BY c DESC)as tn FROM east
WARN :
INFO : Query ID = hive_20201116200245_6ca5200e-1ea5-41ef-8048-ab1b47d4e07e
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1604020633149_0009
INFO : Executing with tokens: []
INFO : The url to track the job: http://cdh0052:8088/proxy/application_1604020633149_0009/
INFO : Starting Job = job_1604020633149_0009, Tracking URL = http://cdh0052:8088/proxy/application_1604020633149_0009/
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/bin/hadoop job -kill job_1604020633149_0009
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-11-16 20:03:02,634 Stage-1 map = 0%, reduce = 0%
INFO : 2020-11-16 20:03:20,130 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.98 sec
INFO : 2020-11-16 20:03:31,485 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 19.18 sec
INFO : MapReduce Total cumulative CPU time: 19 seconds 180 msec
INFO : Ended Job = job_1604020633149_0009
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 19.18 sec HDFS Read: 9532 HDFS Write: 463 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 19 seconds 180 msec
INFO : Completed executing command(queryId=hive_20201116200245_6ca5200e-1ea5-41ef-8048-ab1b47d4e07e); Time taken: 47.407 seconds
INFO : OK
Hive是如何实现分区的
- 建表语句
CREATE EXTERNAL TABLE IF NOT EXISTS category_ods_t
(
categoryID INT COMMENT "产品类别ID",
categoryName STRING COMMENT "产品类别名称"
)
COMMENT "产品目录表"
partitioned by (year string,month string,day string)
- 增加分区
alter table tablename add partition(dt='2020-11-16')
- 删除分区
alter table tablename drop partition(dt='2020-11-16')
窗口函数
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
SELECT *,row_number() OVER(PARTITION BY c ORDER BY c DESC)as tn FROM east
- 为什么要用窗口函数呢
统计班级人数
select classname,count(stuid) as s from student group by classname order by s;
select classname,count(stuid) over(PARTITION BY classname ORDER BY classname DESC) from student
partition by分组后的结果称为“窗口”,这里的窗口不是我们家里的门窗,而是表示“范围”的意思。简单来说,窗口函数有以下功能:同时具有分组和排序的功能,不减少原表的行数
- 几种专用窗口函数的对比
比如给出排序后的数据是100,99,77,77,66
#排名结果:1:100,2:99,3:77,4:77,5:66
row_number() over(partition by regionX order by nameX desc) as tn
#排名结果:1:100,2:99,3:77,3:77,5:66
rank() over(partiition by regionX order by nameX desc) as tn
#排名结果:1:100,2:99,3:77,3:77,4:66
dense_rank() over()
- 聚合函数作为窗口函数
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如看第三行的聚合函数运算后的数据,在使用sum窗口函数后的结果,是对第一行,第二行数据求和,若是第10行,则结果是第一行第十行数据的求和;
同理,其他聚合函数都是针对自身记录、以及自身记录之上的所有数据进行计算;
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
hive对空值的处理
null在hive底层默认是⽤”\N”来存储的,所以在sqoop到mysql之前需要将为null的数据加⼯成其他字符,否则sqoop提示错误,是由 alter table name SET SERDEPROPERTIES(‘serialization.null.format’ = ‘\N’); 参数控制的
- 不同数据类型对空值的存储规则
int与string类型数据存储,null默认存储为 \N;
string类型的数据如果为””,存储则是””;
另外往int类型的字段插入数据“”时,结果还是\N。
- 不同数据类型,空值的查询
对于int可以使用is null来判断空;
而对于string类型,条件is null 查出来的是\N的数据;而条件 =’’,查询出来的是””的数据